
This is a white paper originally written in 2016 for a customer who was building asset tracking systems for information – i.e. tracking databases, documents, messages, backups, etc. There is something quite slippery about this kind of asset that makes it difficult to model. We decided to go back to first principles and work up from there. This (rather long) blog summarises what we found. This is not an easy topic, so not one for casual reading.
Introduction
Modelling information is a tricky business. Information tends to be hard to pin down and is often seen as an intangible thing – at least when compared with physical asset management. Much of this stems from the fact there may be many copies of the same information, and all the things we want to say about the information (metadata) applies equally to each of its copies. Furthermore, the importance of the information itself stems from the fact that it refers to or represents things in the real world (or in some possible future state of it). In the case of the MOD, the information may be sensitive, and Government departments are required to track their handling of sensitive information. This requirement has resulted in those departments seeking to manage discrete sets of information as assets.
We care about the information, all of its instances (i.e. copies of the same document), where they are, what has happened to them, and who has responsibility for the information (and for each of its instances) and what the information is about.
This paper will not attempt to distinguish between information and data, and readers should assume the terms have been used interchangeably. The difference is just context – one person’s data is another person’s information. If you have the ability to interpret the data and how it’s related, you’re likely to call it information. If you don’t, it’s just data.
Ground Rules
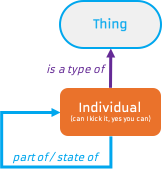
The analysis in this paper follows a series of logical steps. In order to have something to build on though, there have to be some “givens” or axioms. The analysis is broadly based on the BORO process (see Appendix A) and that gives us one main ground rule; everything has to be based on an identifiable physical thing or extent. If a concept has a clearly identifiable physical extent, then we call it an Individual (can I kick it ? yes you can). What that means is that BORO attempts to cut through any linguistic or philosophical debate by starting with physical stuff that exists (or may have existed at some point in time) and working up from there. For that reason, our analysis starts with instances of information (see next section) as those are things we can actually identify has having physical extent.
The second ground rule is that if the concept we’re analysing doesn’t have a physical extent, then it must be either a type of thing (can I kick it ? no you can’t) or some more complex amalgam of stuff that needs to be unpicked into its component physical things, types and relationships (can I kick it ? maybe you can kick some aspects of it, go work out what they are and come back to me[1]).
BORO is also very specific about how to identify when a concept is a type of thing. Types are sets of concepts that have something in common. Examples would be “red things”, “blue things”, “vehicle”, etc. The members of these sets identify their extent – i.e. the extent of the “red things” set is all the physical things that have ever existed that were red. In every BORO analysis you do, you have to ground it in physical reality, so you need to define a set in terms of its members. Sets can overlap, and sets can have subsets:

Venn diagrams are great ways to visualise this kind of analysis
as you can see instantly which sets the things you’re interested in belong to.
It’s a bit more of a stretch when dealing with information, but provided you
keep yourself grounded in that BORO principle of establishing the physical
things first, it still works.
Instances of Information
There may exist many instances (copies) of the same information in different locations – think of all the Gideon’s bibles laying in hotel drawers across the world, or all the copies of today’s Guardian Newspaper sitting in every organic café in Islington. There is a lot that is common about all of these things. They all convey exactly the same information in the same format. BORO tells us that each of the information instances are Individuals (Physical Things) because we can identify their physical extent (e.g. location, size, etc.). This is also true for electronic information which at some point has some physical manifestation such as magnetic images on a disk or electrical charge in memory.
If we know there are instances of information, and they are our grounding point in BORO, what is the information itself ? All these instances convey the same information and refer to the same things, so they very obviously have something in common – all those copies are instances of the information:

We want to identify and work with the information because it’s inconvenient to replicate our modelling for each and every copy. In many cases we don’t care about individual copies, and we only care about the Information itself. In logic and set theory, classes are either viewed as the collections of things that have something in common (sets) or the prototypical idealised concept that all their instances conform to. Whichever of those ways we choose to slice it, we can see that what we’re calling information can only really be identified as the set of all physical things that convey that information. In this analysis, Information Instances are physical things and we can show this as a Venn diagram:

That’s probably a bit counter-intuitive, so let’s use a bit of the BORO process to give us another way of looking at this. The “can we kick it” question is a difficult one for information – we can certainly kick each of its instances. However, it’s unlikely we’d ever do anything to all the instances at once, and often we don’t even account for all the instances. Difficult. Let’s go back to cars. Can we kick VW Golfs ? No, but we can kick each of its instances, and again, we may not want to account for all the instances. Sounds rather similar. We have physical things (the information instances or individual cars) and we have sets of them that share something in common (information conveyed, body style, wheelbase, etc.). Whichever way you look at it, information seems to be a class. Yet even as I write that, I feel uncomfortable with it. Why is that ? Well, this is a personal view, but I think it’s because we learn to classify before we learn to read, and classifying VW Golfs is much more intuitive than classifying something that we never really learned to classify other than by genre.
So let’s test the genre thing. My copy of War and Peace is a copy of a work of fiction. It is a copy of a work of political fiction too.

If I tidy that up a bit, I get:
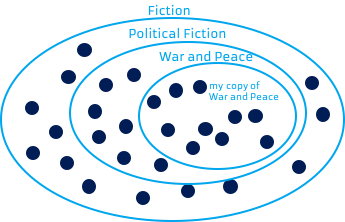
And that looks even more like the Car->VW->VW Golfs pattern we had before.
So we know now that what we’ve called information must, by logical consequence, be a class. That’s a bit counter-intuitive, but most people think of information as being something vaguely intangible. The reason for this vagueness seems to be the fact there are instances and classes, and our language tends to be quite loose in distinguishing between them. We are not so loose in distinguishing between, say, the class of VW Golfs and my VW Golf but that stems from the early childhood process of learning how to classify stuff. A great deal of early childhood development is around classification; cat, dog, animal, person, car, etc. We don’t learn to read (at least not significant amounts of information) until most of us have got the classification stuff hard-wired into our minds. This is my best guess for the reason why we struggle with unpicking and categorising information…
Sense and Reference
…The other reason we struggle with information is that the information must (by definition) be about something. If it wasn’t describing, representing or referring to something, it would just be noise rather than information. It is very common to conflate the information with the thing the information is about. This is particularly prevalent amongst professionals who work with information, and endemic amongst IT professionals. When asked the question directly, such as “are you the same thing as your medical record”, most sane people would answer no. That includes IT folk. Even IT folk who work in medical areas. However, they regularly conflate the two things when not pressed to think about the difference. They use the same identifiers for the patient as the corresponding patient record in implementations, and regularly switch their conversational references between the patient and the patient record without realising they’re doing it. Look out for it next time you’re talking to someone from an IT background about data.
So, our information is about something. Let’s call the topic of our information a “thing”. We can also say that all instances of the same information will be about that thing, so we can logically infer that the Information (the class) is about the thing:

Why do we care ? Well, when we want to model information (e.g. files, records, raw analytics data, etc.) that is about something in the real world, we will almost certainly want to make assertions about the the information as well as the thing it refers to. The creation date of your medical record and your creation date are probably not the same. The current location of your medical record is unlikely to be your current location. When we cut a bit off a patient, we don’t cut a bit out of their medical record (in fact we add something to it).
A lot has been written about sense and reference (the technical name for distinguishing between representation of things and the things themselves) but it’s probably summed up most concisely in Magritte’s The Treachery of Images (Ceci n’est pas une pipe):

The map is not the territory, the word is not the thing. It’s not a pipe, it’s a painting of a pipe. And this is a document about that painting, so now we also know that information can be about information. Weirder still, I just referred to this document, so Information can even be about itself. Information is therefore a special kind of (what we’ve been calling) thing. It is also conceivable that we might have information about a specific information instance – e.g. an essay that refers to Hemmingway’s much treasured and well-thumbed copy “The Famous Five”. Welcome to the rabbit hole. As confusing as that all might be, it is all still logical and we can establish that both information and information instance are just special types of thing.

It’s not exactly intuitive, but we have got here via a series of simple logical steps. Furthermore, this is the strangest part of the analysis, so provided you’ve got your head round this bit, it’s all downhill from here. The takeaways from this are:
- Instances (i.e. copies) of information are physical things (Individuals). This gets a bit tenuous when discussing electronic information, but you can still logically argue that individual logic gates in memory, or magnetic patterns on a disk are instances of information.
- The more general case of Information is the set of all information instances that convey said information. This is, logically, a class because it has instances.
- Information is about something (Thing)
- Information is a type of Thing – i.e. a Class
- Information Instances are Individuals, and Individuals are Things
If we put all that together, so far, we have:

The is a type of relationship is asserting subclassification; that would be a generalization relationship in UML or an rdfs:subClassOf in W3C ontology land. The instance of relationship would be rdf:type in W3C. As an aside, the linked data folks in W3C never really got to grips with the “is about” relationship above, and have come up with some pretty odd workarounds whilst seemingly ignoring the sense-and-reference elephant in the room.
Changing Information
Information persists – what has been said cannot be unsaid. Instances of information are created and destroyed, but the essence of what was conveyed lasts forever[2]. Given that the class persists and the instances are ephemeral, what is actually changing ? If an information instance changes, is it still the same information instance ? If we follow BORO’s principles, physical things are identified by their physical extent. If that extent changes, then it’s no longer the same physical thing. Looking at it another way, if the instance no longer conveys the same information, then it really can’t belong to the same class as it used to. How do we maintain its identity as it changes ? Keeping it simple to start with, let’s imagine a piece of paper on which we write “Mary had a little lamb”. Then, someone comes along and edits it to say “Barry had a leg of lamb”. It definitely changed, and there may be good reasons why we’d want to know it had changed (think legal evidence, compliance, Sarbanes Oxley, etc). How does that fit with the models we’ve established so far ?
We know the two instances are different, but one became the other. Each has different information content, so belong to different Information classes:
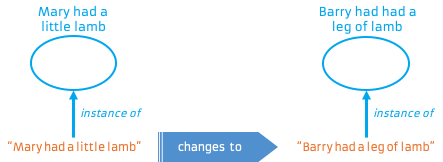
The classes don’t change. They may have existed before these particular instances came into existence, and will continue to exist after the instances are gone. So what we have are two Individuals, each of which is an instance of a different class. Is it important that we consider the persistence of the information instance ? Perhaps if we care about evidence tampering, change history, etc. then we probably do. BORO offers us a solution here. The ontologies that BORO produces generally end up being four dimensional. That all sounds a bit Star Trek, but it’s actually pretty simple; it just means we end up treating time in the same way we treat spatial dimensions. This means something can be in 2016 (e.g. the European Football Championships). It also cleans up a few things:
- Activities are often seen as intangible things. However, in 4D we can identify their extent so they are clearly Individuals
- Data modellers are pretty crap at modelling time. They will tend to use different approaches for modelling durations, change, absolute points in time, etc. 4D cuts through all of that and gives you one and only one way to work with time. It’s not always as convenient or simple as you’d like, but the trade-off with the increased consistency across the model is generally worth it.
- Classes don’t have extent in 4D. This means they are effectively timeless. We can conceive of a class long before any of its members exist. So, keeping with the Star Trek theme, we can talk about class of faster-than-light-speed vehicles even though none of them exist, or probably will ever exist (sorry Trekkies). We can also have classes of things that no longer exist but did exist in the past, such as dinosaurs (sorry creationists).
So, coming back to earth with a bang, how does 4D help us model changing information instances ? There is some sense of a persisting instance, even though it changes. Let’s call this the whole life instance. I’m not sure we can call it an information instance, strictly speaking, as the content it conveys changes, and at some point it will have been a blank piece of paper / disk / memory. This whole life individual was created at some point in a paper mill / electronics factory, and at some point will be destroyed. It had two phases in its life that we’re interested in, where it conveyed two different information contents. We can represent this in what is rather exotically called a “space time map”, which shows space on one axis and time on another:
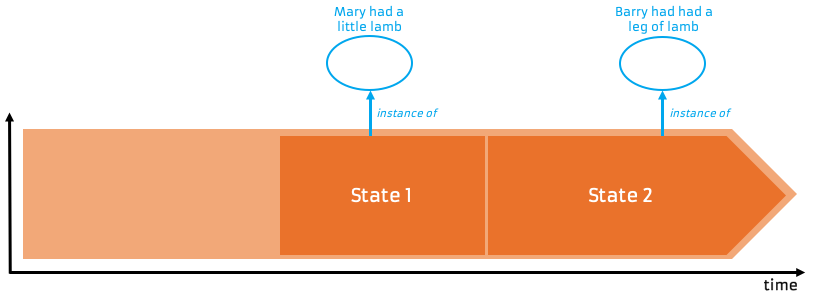
Both states are just parts of the whole. They come into existence at a point in time, and in the case of State 1, cease to exist at another time. Each of these states is an information instance, and they are instances of different information. The whole life individual allows us to maintain the identity as change occurs[3].
This also means we’ve identified another relationship, between Individuals, where one Individual is part of another. In this case, it’s a special kind of part, because it’s all of the Individual for a period of time – i.e. it’s a state-of relationship.
That’s probably enough on this for now. I’ll try and follow up with something more detailed on namespaces at some point. For now, there’s an old blog I wrote on separating object space and name space.
[1] The rather less popular follow-up to Tribe Called Quest’s 1989 hit single
[2] Yeah yeah, all information is destroyed at the event horizon of a black hole, but I don’t live near enough to one to be worried about that. So for all intents and purposes, information persists. All copies may be gone, and it may have long been forgotten by the generations, but the statement had been made and the class established.
[3] For a thought exercise in identity of the whole persisting as the parts change, google “Ship of Theseus” or “Trigger’s Broom”. Other search engines are available.

Recent Comments