
Originally written in 2010 for UK Government paper.
BORO stands for Business Object Reference Ontology. The purpose of the method is to re-engineer disparate data sources into a common model. It is particularly good at semantic analysis – establishing whether two concepts are the same, if they overlap, or if they are unrelated. Traditional methods of data analysis tend to be linguistic, comparing the names of the concepts rather than the things they describe[1]. Some modern methods have introduced a more semantic approach, where the analyst will tend to analyse the meaning behind a word. Although these methods tend to produce more accurate comparisons, a lot of it depends on the analyst’s domain knowledge and linguistic interpretation.
BORO is different. The process itself ignores the names of things. Instead, the analyst is forced to identify individual concepts by their extent. In the case of physical objects, this is their spatial/temporal extent. For types of things, the extent is set of things that are of that type. The BORO methodology is best summarised as a flowchart:
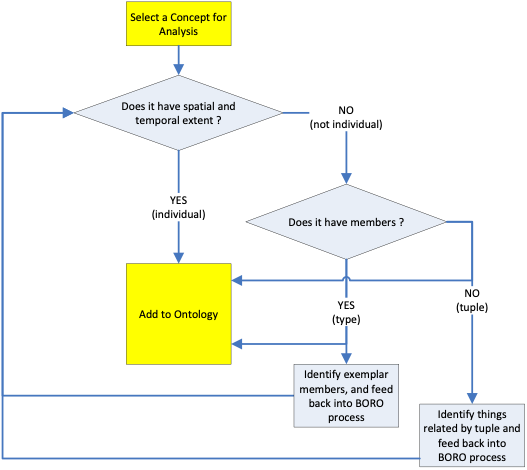
As an example, take “Waterloo Bridge” as a concept. The first thing we ask is “does it have spatial and temporal extent ?”. It has spatial extent; it spans the River Thames. However, when we examine the temporal extent we realise there have been two bridges at that site. The first, built in 1817 (two years after the battle of Waterloo) was demolished in 1920. The bridge that stands there now was built in 1942. This analysis has immediately highlighted a problem with a name-based approach – there are two bridges of that name, which one are we referring to ? At this point, the analyst can add one or both of the bridges to the ontology, then apply the appropriate names to each (see later section on the IDEAS Naming Pattern).
The process also works for types of things. Take “bridges” as a concept. It doesn’t have spatiotemporal extent, so we go to the next question “does it have members ?”. It does – the members are all the bridges in the world. We then identify some exemplar members – e.g. Waterloo Bridge. At this stage, it is advisable to identify exemplars that are “on the edge” of the set – e.g. things that may or may not be bridges – e.g. pontoons, bridging vehicles, etc. so as to accurately identify the extent of the type.
The final concept covered by the process is the tuple. A tuple is a relationship between things. If the concept under analysis is neither a type nor an individual, then it must be a tuple. We identify the things at the end of the tuple then add it to the ontology. The next section provides more background on individuals, types and tuples.
BORO is perhaps easier to understand with an example. Take a database table containing information about personnel:

As human readers, we can infer that there are a number of people and they work in various departments, and they may report to a line manager. However, the information is simply stored as text and numeric fields. Database design techniques such as normalisation go some way towards rationalising data like this, but the structure is still a structure of data rather than a structure of real-world objects. If we want to integrate this information with other information about building locations, salary payments, health, departmental budgets, diaries, projects, etc. the traditional approach is to compare the fields from the various sources and look for matching IDs, names, etc. This does not really add any value though, and names (or words in general) are notoriously unreliable ways to identify things – especially across different communities of interest.
The BORO way is different. Taking the first and second columns, we can see there are people. They are definitely individuals, so we can add them to the ontology straight away. Each of these individuals has two identifiers – their names, and the database ID (there could also be national insurance number, for example). These identifiers are added to the ontology, along with their contexts. Then we look at the departments and we can see again that these are individuals. The interesting thing though is the relationship between the person and the department. BORO relies on physical extent, so the relationship has to be expressed in those terms. At first glance the people are part of the departments. On further analysis, it is apparent that they haven’t always been part of the department, nor are they part of the department 24hrs a day. This means the people and the departments overlap (spatially and temporally), with the overlapping part being their participation in the ongoing efforts of the department.
This approach may seem overly precise, but it is guaranteed to come up with the same structure regardless of how the original data was presented. This means if another data source also carries information about the same things, it will be immediately apparent of they’re the same if they map onto the same structure.
Why BORO ?
BORO works best on legacy data. The dirtier the better. In fact, what IT specialists often call data quality problems are usually problems in the design of the database – users can’t find a place to put the information they need to store, so they wedge it into inappropriate fields. BORO looks for these cases and uses them to derive the truth of what the users are actually doing – in other words, it’s led by business rather than IT.
As for “why BORO ?”, it may be best to look at what is done traditionally. Information systems design usually starts with a process model or a set of written requirements (or user stories). Process models are notoriously inaccurate, and requirements specification are often wide of the mark. They rely on either interviewing or monitoring employees who are either suspicious of the motives or have a poor understanding of their own role. The “information flows” in a process model, or just the raw requirements are then used by a data modeller to develop a data model. There are no hard and fast rules for this, and each modeller will put their own slant on the process. Data modelling is supposed to be based on set theory, but three thousand years of the best minds in maths and philosophy are usually cast aside when the modeller decides to “put an entity here, a relationship there”. The data model then goes for implementation. This usually either means ignoring it and building something that looks cool (or worse, whatever you built last time), or being forced to buy an off-the-shelf solution that has its own model. It is time for a change in how we build IT systems.
Further Reading
Chris Partridges book covers nearly all of this. I am always acutely aware that Chris’s desire to be precise sometimes means the book can be hard to follow. All I’ve attempted to do in this paper is put some of his ideas in laymen’s terms. In turn, I think Chris would argue he’d attempted to do the same with ideas from Quine, Strawson, Goodman, Frege and Russell. Maybe I’ve watered it down too much, in which case please read all the references below.
Business Objects: Re-Engineering for Re-Use, Partridge (ISBN0955060303)
[1] The distinction between representation (the names and definitions of concepts) and the things in the real world those concepts describe is central to the BORO method. The idea is to remove the naming from the analysis process and focus on the physical reality of the concepts.

Recent Comments